The algorithm described here is what is known as asynchronous, single-pool branch and cut. The term asynchronous was discussed in Section 3. The term single-pool refers to the fact that there is a single central list of candidate subproblems to be processed, which is maintained by the tree manager. For a description of other types of parallel branch and bound, see [10].
The master process begins by reading in the parameters and problem data. After initial I/O is completed, user-written routines for finding an initial upper bound and constructing the root node are executed (see Section 5.1 for details), the tree manager process is spawned, and the data for the root node are sent to it. The tree manager in turn spawns the cut pool processes, the linear program processes, and the cut generator processes. Each LP process has a single cut generator associated with it which serves requests from that LP process alone. The root node is placed on the candidate node list and the initial upper bound is set equal to the best heuristic upper bound found. All LPs are marked as idle. The algorithm is ready for execution.
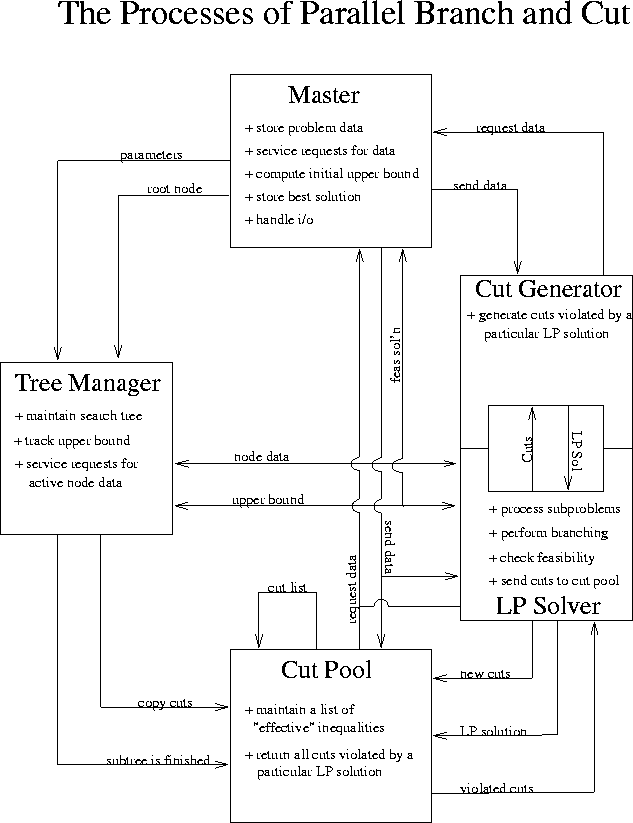
Figure 4: Schematic overview of the parallel branch and cut algorithm
In the steady state, the tree manager controls the execution by maintaining the list of candidate subproblems and sending them to the LP processes as they become idle. The LP processes receive nodes from the tree manager, process them, branch (if required), and send back the identity of the chosen branching object to the tree manager, which in turn generates the children and places them on the list of candidates to be processed. A schematic summary of the algorithm is shown in Figure 4, although some of the ideas in this summary have not yet been presented. The preference ordering for processing nodes is a parameter that can be set by the user. The default is to choose the node with the lowest lower bound to be processed next, because this is in some sense the node that is most likely to be on a path to an optimal solution. The concepts of diving and search chains, introduced in Section 5.3.1, extend this basic approach.